
⚠️ Attention : cet article est en grande partie purement technique. Je recommande aux lecteur·ices d'avoir quelques bases en Bash pour suivre les parties les plus complexes. Si l'aspect technique nous vous intéresse pas, vous pouvez tout de même lire le début de l'article, et regarder le site réalisé.
L'été 2020, le COVID bat son plein et je suis confinée à la campagne. J'eus alors réalisé un projet assez aventureux : sur la requête d'une connaissance, j'ai transposé le contenu d'un vieux CD-ROM de plus de 10 ans en site internet au goût du jour.
Le CD-ROM contenait environ 5Go de photos des œuvres d'un peintre, accompagnées de textes explicatifs. Le tout était interactif, avec des galeries d'images aux transitions dignes de PowerPoint. Il était traduit en trois langues et contenait quelques centaines de pages. Il avait été réalisé à la main, codé dans un mélange de code lambda et de HTML.
Mon objectif était d'en tirer les informations (textes et images) et d'en réaliser un site web statique avec le même contenu, les mêmes divisions de pages et galeries, avec un design simple plus actuel.
On part de loin.


Récupération des données
Pour ce projet ambitieux, je possédai uniquement le CD-ROM, gracieusement envoyé par la poste par la connaissance à l'origine de la requête. Bien qu'il fût conçu pour Windows, je pus aisément le lancer avec Wine.
En extraire les images fut relativement simple, tout se trouvait dans les fichiers du CD. Concernant les textes... c'était une autre paire de manches. Ils n'existaient nulle part ailleurs que dans l'exécutable, et je n'étais pas réellement prête à m'exercer au reverse là-dessus.
Me voilà donc à envoyer un mail à la personne ayant développé ce CD-ROM, une dizaine d'années plus tôt. Heureusement, j'eus une réponse plutôt positive, et je me mis à discuter avec cette personne, alors confinée de l'autre côté de la Terre.
En une petite semaine, je reçus quelques fichiers dont un de 17 000 lignes contenant le code du logiciel ainsi que les textes traduits en français, anglais et néerlandais.
Concevoir un site internet ?
La connaissance à l'origine de la requête possédant déjà un site Wordpress, l'option de partir sur ce CMS était naturellement évoquée. Cependant, Wordpress étant plutôt conçu pour écrire ses articles manuellement, cela aurait été une charge de travail monstrueusement chronophage et ennuyante. Il aurait été certainement possible d'automatiser ce processus, mais je ne m'y connais pas assez en Wordpress pour cela.
À cette époque, je venais alors de concevoir mon site, réalisé avec Zola, un générateur de sites statiques. En sachant que le résultat attendu (pages fixes, galeries d'images) allait être statique, cela me parut être un bon choix.
Je partis donc dans l'idée d'écrire des scripts Bash qui allaient découper le code source que j'avais reçu, en extraire les informations importantes, et générer des pages statiques dans le format de Zola.
⚠️ Attention, à partir d'ici, l'article devient plus technique. Si cela ne vous intéresse pas, vous pouvez sauter cette partie et lire la fin de l'article.
Étude du code source
Un rapide coup d'œil permit de comprendre l'architecture du code source. Le code est séparé en cards, des pages, qui contiennent les textes traduits en différentes langues parsemées de divers balises HTML, et le chemin vers les images.
*** card 80
frTitre=<h1 class='fr'>« Poèmes-sculptures »</h1>
enTitre=<h1 class='en'>« Poems Sculptures »</h1>
nlTitre=<h1 class='nl'>« Gedichten - Beelden »</h1>
** field id=11928 rect=132,160,840,1000
* frHtmlTxt=
<div class='fr'>
Cette possibilité de création commune, à [...]
</div>
* enHtmlTxt=
<div class='en'>
<font size="14">Ever since we met we have always wanted the possibility to work together, [...]
</div>
* nlHtmlTxt=
<div class='nl'>
Sinds we elkaar ontmoetten, hebben we altijd al gewenst om samen te werken, [...]
</div>
** image id=10571
rect=140,179,471,398
src=./card_300504/mini/aGuidi_7662.jpg
[...]Tout le fichier se compose de la même manière, avec un total de 279 pages.
Division du code source
Ma première tâche fut donc de diviser ce code en un fichier par card, permettant ainsi de travailler séparément sur chaque. J'ai pour cela utilisé la commande csplit.
#!/bin/bash
csplit textes.txt "/*** card/" '{*}' -n 3 -f 'card'Dans cette commande,
csplitdivise le fichiertextes.txtselon le pattern/*** card/, que l'on retrouvait systématiquement au début de noscards;{*}permet de répéter l'action de division autant de fois que nécessaire ;-nindique le nombre de chiffres dans le numéro de la carte (par exemple,1sera001) ;-findique un préfixe pour la nomenclature des fichiers sortants.
Cela nous donne les fichiers suivants :
> ls
card001 card012 card023 card034 card045 card056 card067 card078
card002 card013 card024 card035 card046 card057 card068 card079
[...]Création des pages web
Une fois la séparation faite, il fallut extraire le contenu, pour en créer des pages dans le format attendu par Zola. Cela n'est pas très complexe techniquement, il n'y a que des echo, cat, cp, sed, grep... La seule complication réside dans l'utilisation de nombreuses variables dans tous les sens.
Commençons donc par créer un squelette de site Zola avec la commande :
zola init zola_sitePour le fonctionnement général de Zola, je vous réfère à mon article Zola : Guide d'utilisation pratique. Sachez juste que toutes les pages du site créé se trouveront dans le dossier content.
Nous allons commencer par itérer sur les fichiers que nous venons de créer :
for f in $(ls textes) ; do
echo Processing $f... ;
[...]Ici, f sera le fichier (et donc le contenu notre future page web) sur lequel nous itérons, à l'aide du ls.
Premièrement, nous allons récupérer le chemin de notre fichier, son numéro, et créer un dossier qui contiendra la page web dans notre site.
CARD_FILE="textes/$f"
LINK=$(echo $f | grep -oE '[0-9]*')
FOLDER="zola_site/content/$LINK"
mkdir -p $FOLDERNous allons ensuite créer un fichier par langue, et appeler la fonction generate_index(), placera le contenu texte approprié dans les fichiers. À noter qu'en Bash, il n'y a pas besoin de parenthèse pour appeler une fonction !
FR="fr"
EN="en"
NL="nl"
FILE_FR="$FOLDER/index.$FR.md"
FILE_EN="$FOLDER/index.$EN.md"
FILE_NL="$FOLDER/index.$NL.md"
generate_index "$FR"
generate_index "$EN"
generate_index "$NL"L'action est un peu rébarbative, puisqu'il faut l'effectuer avec chaque langue. Dans une version plus élaborée, cela aurait pu être automatisé également.
Extraction du titre et des textes
Nous allons donc étudier la fonction generate_index(). L'idée générale consiste à utiliser un template de page de Zola réalisé à l'avance, d'y remplacer les variables nécessaires, et enfin, d'extirper le texte de notre fichier pour le traiter et l'insérer dans la page.
Voici un aperçu du template. %TITLE est une variable temporaire qui sera remplacé par le réel titre, page.html est le template : tout ce qui se trouve avant et après notre contenu, en HTML : le menu, la pagination... Ce fichier aura été réalisé manuellement. Enfin, la variable %NUM%, correspondant au numéro de la page, nous servira pour la pagination dans le template.
+++
title = "%TITLE%"
template = "page.html"
[extra]
num = "%NUM%"
+++Et voici la fonction generate_index().
function generate_index() {
FILE="$FOLDER/index.$1.md"
cp template-page.md $FILE
TITLE=$(cat $CARD_FILE | grep -oE "$1'>(.*?)<" | cut -c 5- | sed 's/.$//' | sed 's/"/”/g')
sed -i "s|%TITLE%|$TITLE|g" $FILE
sed -i "s|%NUM%|$LINK|g" $FILE
TEXT=$(cat $CARD_FILE | sed -n "/div class='$1'>/,/div>/p" | sed "s/<div class='$1'>//g" | sed 's/<\/div>//g' | python3 -c 'import html,sys; print(html.unescape(sys.stdin.read()), end="")' | tr -d '\015' | sed 's/\*/\\\*/g' | sed 's/<font size="[0-9][0-9]">//g' | sed 's/<\/font>//g')
}Nous copions le template dans le dossier que nous avons créé. En Bash, lorsqu'une fonction prend des arguments comme c'est le cas ici, ils n'ont pas de noms déterminés. Cela sera donc $1, $2... À l'extérieur d'une fonction, ces arguments sont ceux passés au script, en ligne de commande. Dans notre cas, l'argument $1 sera la langue passée pour générer le fichier.
Nous commençons par récupérer le titre. Nous utilisons la commande grep, car nous savons qu'il sera toujours de la forme frTitre=<h1 class='fr'>« Poèmes-sculptures »</h1>. Le -o de notre grep signifie only-match : nous essayons de récupérer le moins de caractères possibles autour de notre titre. cut et sed permettent ici d'enlever les caractères en trop.
Une fois notre titre obtenu, nous remplaçons la variable temporaire %TITLE% avec sed. J'utilise des | au lieu de / dans le sed afin de préserver d'éventuels / qui seraient dans le titre.
Nous allons ensuite devoir récupérer le texte et le traiter. Cela sera fait de manière similaire, à coups de grep et de sed, pour enlever tout le HTML qui nous est inutile.
Quelques petites subtilités :
python3 -c 'import html,sys; print(html.unescape(sys.stdin.read()), end="")'va nous permettre de remplacer les caractères d'échappement HTML présents dans le fichier d'origine (é,à...) par leur réel caractère ;tr -d '\015'nous permettra de supprimer un certain caractère spécial, un retour chariot de Windows, qui s'est glissé absolument partout dans le fichier d'origine.
Nous avons maintenant une page web par langue avec un titre et du texte ! Il ne nous manque plus que les images.
Extraction des images
Tout comme pour les textes, l'extraction des photos se réalisera à coup de grep et de sed. Commençons par faire une boucle sur les images dans le fichier :
while read -r line ; do
[...]
done <<< "$(cat $CARD_FILE | grep src | grep card)"L'utilisation du triple chevron <<< permet passer au while ce qui se trouve après le done.
La gestion des images nous mème tout de même à une problématique supplémentaire : comment faire la liaison entre la nomenclature des images dans le fichier et celles que j'ai de mon côté ? En effet, l'arborescence des fichiers n'est pas la même...
Fort heureusement, les chemins des images indiqués dans le fichier et les dossiers que je possède disposent un numéro en commun, par exemple, dans le cas de src=./card_300504/mini/aGuidi_7662.jpg, le dossier de mon côté se nomme 300504 Où sont les yeux. Le nom de l'image reste le même. Nous allons donc utiliser ce point commun pour récupérer les images, et les joindre dans nos pages web.
MEDIA_FOLDER="cd_ressources/media/"
ID=$(echo $line | grep -oE '[0-9]{6}/' | sed 's/\///g')
IMG_FILE=$(basename "$line" | tr -dc '[:blank:][:alnum:]_.')
IMG_FOLDER=$(ls "$MEDIA_FOLDER" | grep $ID)
IMG_PATH="$MEDIA_FOLDER$IMG_FOLDER/$IMG_FILE"
IMG_PATH=$(echo $IMG_PATH | sed "s/'$'\r//g")
cp "$IMG_PATH" $FOLDERJ'ai à ma disposition un fichier de légendes pour les images. Je vais donc m'en servir pour les alt de mes images. Ces légendes sont toutes les unes à la suite des autres, précédées du nom de l'image qu'elles décrivent. Je vais donc les récupérer. Dans le cas où il n'y a pas de légende, je la remplace par un texte alternatif.
LGD_ID=$(echo $IMG_FILE | grep -oE '[0-9]{3,10}')
if [ ! -z "$LGD_ID" ]; then
LEGEND=$(cat $LEGEND_FILE | grep $LGD_ID | cut -d ' ' -f 2-999 | tr -d '\015')
fi
if [ -z "$LEGEND" ]; then
LEGEND="Guidi"
fiMaintenant que nous avons copié les photos et que nous avons leur légendes, nous pouvons les insérer dans nos pages web. Il y a une subtilité : s'il y a moins de 4 images, nous allons les afficher en pleine page, sinon, nous allons créer une galerie de photos.
nb_img=$(cat $CARD_FILE | grep src | grep card | wc -l)
if [[ $nb_img -lt 4 ]]; then
write_everywhere ""
write_everywhere ""
fi
if [[ $nb_img -gt 3 ]]; then
write_everywhere "{{ gallery() }}"
fiDans cette partie, je récupère d'abord le nombre d'images. Ensuite, s'il y en a moins de 4, je les affiche en suivant la procédure en markdown pour l'affichage d'image : . La fonction write_everywhere() est très simple, elle rajoute juste à la fin des trois fichiers de langue ce qu'on lui donne en argument.
Ensuite, s'il y a plus de 4 images, nous créerons plutôt une galerie, avec un shortcode Zola créé à la main.
Voici à quoi ressemble le shortcode :
<div class="gallery">
{% for asset in page.assets %}
{% if asset is matching("[.](jpg|png)$") %}
<a class="gallery-img" href="{{ get_url(path=asset) }}" onclick="zoom_in(this); return false;">
<img class="gallery-img" src="{{ resize_image(path=asset, width=280, height=280, op="fill") }}" />
</a>
{% endif %}
{% endfor %}
</div>Ce code prend tous les fichiers du dossier courant, et s'il s'agit d'images, il les affiche en miniature. Cliquer sur une miniature déclenche quelques lignes de JavaScript pour afficher l'image en grand et circuler entre les images.
let g_prevElement = null;
let g_nextElement = null;
function close_popup() {
let popup_img = document.getElementById("media-img");
let popup = document.getElementById("media-popup");
popup.style.display = "none";
popup_img.style.display = "none";
}
function zoom_in(elem) {
let popup = document.getElementById("media-popup");
let popup_img = document.getElementById("media-img");
popup.style.display = "flex";
popup_img.setAttribute("src", elem.getAttribute("href"));
popup_img.onload = function() {
popup_img.style.display = "flex";
}
g_prevElement = elem.previousElementSibling;
g_nextElement = elem.nextElementSibling;
let prev_arrow = document.getElementById("media-arrow-left");
let next_arrow = document.getElementById("media-arrow-right");
if (g_prevElement == null) {
prev_arrow.style.setProperty("pointer-events", "none");
prev_arrow.style.opacity = "0";
}
else {
prev_arrow.style.opacity = "unset";
prev_arrow.style.setProperty("pointer-events", "unset");
}
if (g_nextElement == null) {
next_arrow.style.setProperty("pointer-events", "none");
next_arrow.style.opacity = "0";
}
else {
next_arrow.style.opacity = "unset";
next_arrow.style.setProperty("pointer-events", "unset");
}
}
function prev() {
if (g_prevElement != null) {
zoom_in(g_prevElement);
}
}
function next() {
if (g_nextElement != null) {
zoom_in(g_nextElement);
}
}Nous en avons maintenant terminé avec le script Bash ! Vous pouvez le retrouver complet ci-dessous.
#!/bin/bash
MEDIA_FOLDER="cd_ressources/media/"
LEGEND_FILE="cd_ressources/legendes.txt"
FR="fr"
EN="en"
NL="nl"
# Écrire une ligne dans toutes les langues
function write_everywhere() {
echo "$1" >> $FILE_FR
echo "$1" >> $FILE_EN
echo "$1" >> $FILE_NL
}
# Générer le fichier index.md, qui contient le contenu de la page web en Markdown
function generate_index() {
FILE="$FOLDER/index.$1.md"
cp template-page.md $FILE
TITLE=$(cat $CARD_FILE | grep -oE "$1'>(.*?)<" | cut -c 5- | sed 's/.$//' | sed 's/"/”/g')
sed -i "s|%TITLE%|$TITLE|g" $FILE
sed -i "s|%NUM%|$LINK|g" $FILE
# Retirer toute trace d'HTML dans le Markdown
TEXT=$(cat $CARD_FILE | sed -n "/div class='$1'>/,/div>/p" | sed "s/<div class='$1'>//g" | sed 's/<\/div>//g' | python3 -c 'import html,sys; print(html.unescape(sys.stdin.read()), end="")' | tr -d '\015' | sed 's/\*/\\\*/g' | sed 's/<font size="[0-9][0-9]">//g' | sed 's/<\/font>//g')
}
# Séparer le fichier de 17 000 lignes en cartes
mkdir -p textes
cp CD_textes.txt textes/
cd textes
csplit CD_textes.txt "/*** card/" '{*}' -n 3 -f 'card'
rm card000
cd ..
# Passer sur chaque carte pour en extraire le contenu et en faire une page Markdown
mkdir -p content_test
for f in $(ls textes) ; do
echo Processing $f... ;
CARD_FILE="textes/$f"
# Récupérer le numéro de la carte pour créer le dossier
LINK=$(echo $f | grep -oE '[0-9]*')
FOLDER="zola_guidi/content/$LINK"
mkdir -p $FOLDER
# Créer un fichier par langue
FILE_FR="$FOLDER/index.$FR.md"
FILE_EN="$FOLDER/index.$EN.md"
FILE_NL="$FOLDER/index.$NL.md"
generate_index "$FR"
generate_index "$EN"
generate_index "$NL"
# Extraire les images
nb_img=$(cat $CARD_FILE | grep src | grep card | wc -l)
while read -r line ; do
ID=$(echo $line | grep -oE '[0-9]{6}/' | sed 's/\///g')
IMG_FILE=$(basename "$line" | tr -dc '[:blank:][:alnum:]_.')
IMG_FOLDER=$(ls "$MEDIA_FOLDER" | grep $ID)
IMG_PATH="$MEDIA_FOLDER$IMG_FOLDER/$IMG_FILE"
IMG_PATH=$(echo $IMG_PATH | sed "s/'$'\r//g")
cp "$IMG_PATH" $FOLDER
# Gérer les légendes
LGD_ID=$(echo $IMG_FILE | grep -oE '[0-9]{3,10}')
if [ ! -z "$LGD_ID" ]; then
LEGEND=$(cat $LEGEND_FILE | grep $LGD_ID | cut -d ' ' -f 2-999 | tr -d '\015')
fi
if [ -z "$LEGEND" ]; then
LEGEND="Guidi"
fi
if [[ $nb_img -lt 4 ]]; then
write_everywhere ""
write_everywhere ""
fi
done <<< "$(cat $CARD_FILE | grep src | grep card)"
### Créer une gallerie lorsqu'il y a plus de 3 images
if [[ $nb_img -gt 3 ]]; then
write_everywhere "{\{ gallery() }}"
fi
done;Templates, CSS et page principale
Nos pages sont presque terminés ! Il leur manque juste un peu d'habillement. Le template page.html, dont nous avons parlé plus tôt, est là pour ça.
{% import "macro.html" as macro %}
<!DOCTYPE html>
<html>
<head>[...]</head>
<body>
[...]
<div class="parent-container">
{% block nav %}
{% if lang == "fr" %}
{% include "nav.html" %}
{% elif lang == "en" %}
{% include "nav.en.html" %}
{% elif lang == "nl" %}
{% include "nav.nl.html" %}
{% endif %}
{% endblock nav %}
<div class="page">
<div class="language">
{% for language in page.translations %}
<a href="{{language.permalink}}"><img class="flags" src="/{{language.lang}}.png"/></a>
{% endfor %}
</div>
<h1>{{page.title}}</h1>
{% include "arrows.html" %}
{{ page.content | safe }}
{% include "arrows.html" %}
</div>
</div>
</body>
</html>Le template permet à toutes les pages d'avoir la même structure :
{% block nav %}permet d'afficher le menu, en fonction de la langue choisie. Il s'agit d'une barre verticale sur la gauche, facilitant la navigation. Le menu est l'une des rares choses à avoir été fait entièrement manuellement, faute de réelle automatisation possible.- la boucle
{% for language in page.translations %}permet d'afficher des petits drapeaux pour les langues disponibles. Cliquer sur un drapeau permet traduire le site dans la langue choisie. {% include "arrows.html" %}affiche des flèches pour la page précédente et suivante. Il est appelé deux fois car il s'affiche avant et après le contenu de la page. Le fichierarrows.htmlest un template simple, qui utilise la variablenumdéfinie plus tôt pour renvoyer le lien des pages précédentes et suivantes. Il gère également les exceptions des premières et dernières pages, où seulement une des deux flèches s'affiche.
Il a fallu rajouter un peu de CSS ensuite, afin de rendre le tout cohérent et au goût du jour, puis rajouter une page principale, présentant le contenu. Le tour est joué !
Relectures et vérifications manuelle des pages
Le site était enfin fonctionnel, les pages étaient toutes générées. Il a fallu cependant repasser sur chaque pages pour vérifier si tout était en ordre. En effet, le CD comportait beaucoup d'exceptions, qu'il a fallu corriger à la main.
Ce fut par exemple :
- Des images dont le nom ne correspondait pas ;
- Une partie du site codée autrement, que j'ai rassemblé manuellement en une seule galerie;
- Des textes en plusieurs pages que j'ai dû réassembler ;
- Des mises en pages ratées...
Cette relecture finie, j'ai pu présenter mon travail à ma commanditaire. Il fallut, encore une fois, repasser sur plusieurs éléments à sa demande, surtout au niveau du contenu.
En tout, je mis environ trois semaines pour réaliser ce site. Le défi en valait la chandelle, l'expérience était intéressante et instructive bien que quelques peu acrobatique.
Vous pouvez maintenant le retrouver à l'adresse suivante : guidi.anniejeanneret.fr.
Voici quelques photos du résultat final :


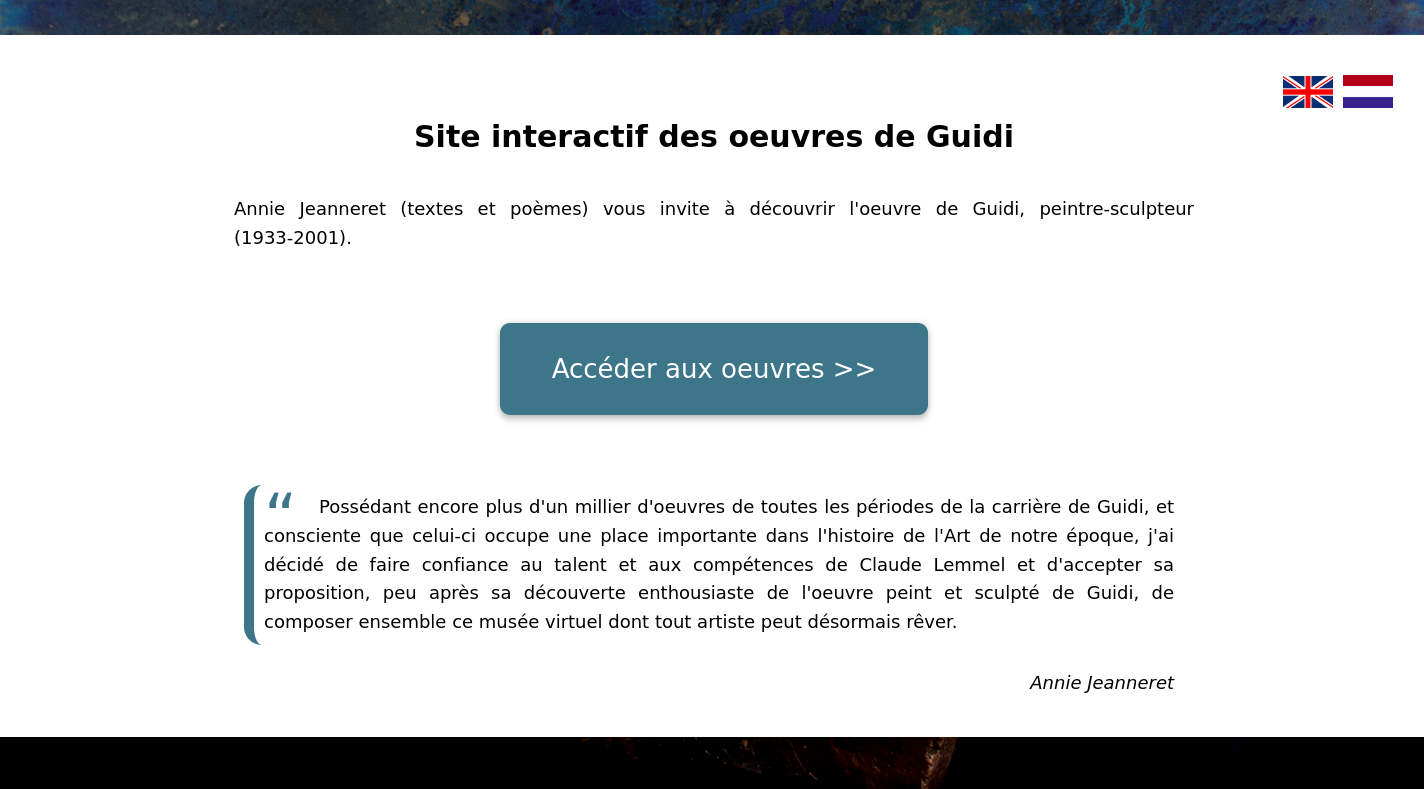
Merci de votre lecture,
Brume